- 本文是京东JData算法大赛-高潜用户购买意向预测和腾讯社交广告高校算法大赛的经历和总结
JDATA
- 任务:通过数据挖掘的技术和机器学习的算法,构建用户购买商品的预测模型,输出高潜用户和目标商品的匹配结果,为精准营销提供高质量的目标群体
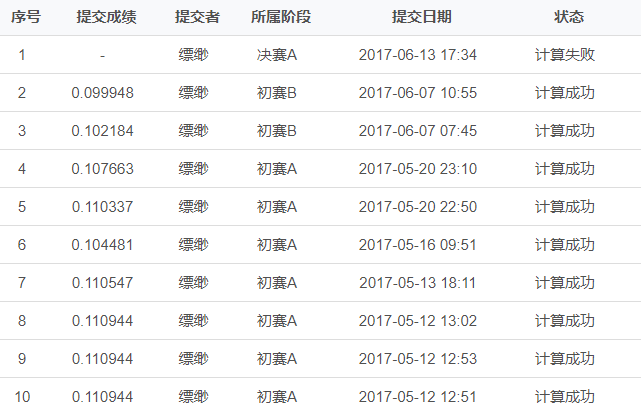
- 参赛队伍4240 我的排名342

JDATA算是我第一次参加的大型带奖金比赛 =#= 大约是2017.4月我被我的好友机器变得更残忍拉入机器学习的坑。然后推荐我去kaggle打入门的house prices和digit recognizer。这时候JDATA已经开赛了,但萌新入门,完全不会。
还是先看kaggle上的kernels做入门题吧。4.16把houseprice做到1100名。在做house price时还不会处理非数值型数据,就简单把数值型的筛出来,然后用SVM跑了下。pandas也基本不会用(当时只是会python基础语法)。代码仅仅50行吧。
好歹有了点成绩,虽然很烂,但也可以稍稍激励下自己嘛。digit recognizer 到没有做出来,debug也不成功,放弃了。
这时候,JDATA也开了3星期左右了。 想着混混感受下氛围的原则,下载数据,准备开搞。在群里潜水了一段时间,发现有规则和模型2条路。模型,暂时不会用,先试试规则吧。比如前几周加到购物车但没有购买的,作为目标用户的购买意向物品。试了几个,发现效果还可以,最好的提交排名达到了600名。怎么办,语法有瓶颈而且规则确实不熟悉,不知道该怎么提分了。还是看看模型吧。
数据放在几个表里,怎么才能提到一起呢,merge一下。非数值型的如月份怎么办,先不管,凉拌,把数值型的弄到一起,用svm和linear regression跑了下 == 不出所料,很烂。这时候知识不够了,上网看看有人介绍思路没。发现了个时间滑动窗口特征的构造。(那个时候还不会自己写,于是找了个处理时间的框架,把代码改了用)。好了,时间处理好了。模型跑一跑,吐血,还是不怎么样,没有到前500。看了下群里推荐xgboost(当时也不了解这是什么,只知道这个工具包很厉害)。想着,下载安装跑一遍,看看效果。结果安装xgboost就让我弄了2天 = =(拖延症 + 烦躁)。好了, 开始运行(也不会调参),发现我的8G内存跑的炸了- -
好吧,不能全数据跑,就截取几个时间点做train吧。然后请教了下别人设置的参数,直接放进去(别打我),再加上debug看kernel,进复赛了 (开心!)
然而发现复赛数据集实在是大,放弃继续弄JDATA了。
腾讯社交广告赛
任务:预测App广告点击后被激活的概率:pCVR=P(conversion=1 | Ad,User,Context),即给定广告、用户和上下文情况下广告被点击后发生激活的概率。
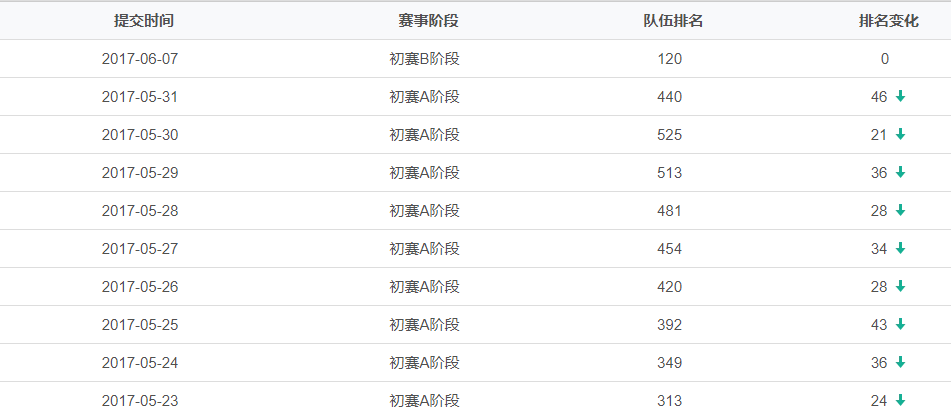
1500个参赛队 排名120
这是紧接着JDATA后的比赛,推荐算法类的。在打完JDATA后,知道了如何建立模型,对时间进行操作,但如何特征工程其实还是一头雾水。比赛中,尝试了tfidf、笛卡尔积特征。效果不错
比赛中2次差点放弃,1内存8G实在是吃力,2成绩在自己努力下波动性提高,名次却平稳增长== 欲哭无泪。
训练集构造:
- 滑窗
- tfidf特征:主要是用作处理< userID,AppID >这样的一对多 并由此延伸出< userID,cate1,cate2 >这样的tfidf特征
- 笛卡儿积特征:主要是两两一起的统计特征
采用xgboost单模型(那时仍然不会调参、哭)
好歹擦边进了复赛= = 然后苦于数据集太大和要期末考试,没有继续打了。
总结:
- 扯淡一个人比赛,又苦又累,新人更是如此,还好我有个朋友可以帮我指明下一步该如何提高。和大佬组队就可以打酱油啦~ 但收获可能会少些,毕竟他们目前的知识比我高太多,难以消化。
- 需要提高编程能力: 内存并不是瓶颈,采用数据抽样,就可以解决内存计算问题而且提高了效率。
- 这2次比赛都没有很好的特征工程,要从业务出发,多想。
- 调参和stacking都很重要(这部分调参可以写个库)
- 有真实数据使用真是太爽啦,比赛有了进步就是好事~